
Kubernetes 开发 SpringCloud (四)、Kubnernetes 部署 Zipkin 搭配 Kafka+ElasticSearch 实现链路追踪
文章目录
!版权声明:本博客内容均为原创,每篇博文作为知识积累,写博不易,转载请注明出处。
相关博文:
- Kubernetes 开发 SpringCloud (一)、使用SpringCloud Kubernetes组件进行服务发现
- Kubernetes 开发 SpringCloud (二)、使用 SpringCloud Kubernetes 组件进行动态配置
- Kubernetes 开发 SpringCloud (三)、使用 SpringCloud Feign 进行 SrpingCloud 服务间的通信
- Kubernetes 开发 SpringCloud (四)、Kubnernetes 部署 Zipkin 搭配 Kafka+ElasticSearch 实现链路追踪
系统环境:
- Kubernetes 版本:1.14.0
- SpringCloud Feign 版本:2.1.2.RELEASE
- SpringCloud Kubernetes 版本:1.0.2.RELEASE
- 示例部署文件 Github 地址:https://github.com/my-dlq/blog-example/tree/master/springcloud/springcloud-kubernetes/springcloud-kubernetes-sleuth-demo
一、链路追踪介绍
为什么要链路追踪:
随着互联网发展,分布式化应用越来越流行,微服务业务越来越复杂化,这些组件共同构成了繁杂的分布式网络,那现在的问题是一个请求经过了这些服务后其中出现了一个调用失败的问题,但具体的异常在哪个服务引起的就需要进入每一个服务里面看日志,这样的处理效率是非常低的。所以链路追踪技术孕育而生,让分布式应用引入链路,在发咋分布式环境下收集链路日志,分析服务间依赖、耗时、错误信息,这样当遇到问题时候能够快速定位问题所在。
链路追踪简介:
分布式调用链其实就是将一次分布式请求还原成调用链路。显式的在后端查看一次分布式请求的调用情况,比如各个节点上的耗时、请求具体打到了哪台机器上、每个服务节点的请求状态等等。
Zipkin 简介:
Zipkin 是一款开源的分布式实时数据追踪系统,由基于 Google Dapper 的论文设计而来,由 Twitter 公司提供开源实现,主要功能是聚集来自各个异构系统的实时监控数据,和微服务架构下的接口直接的调用链路和系统延时问题。
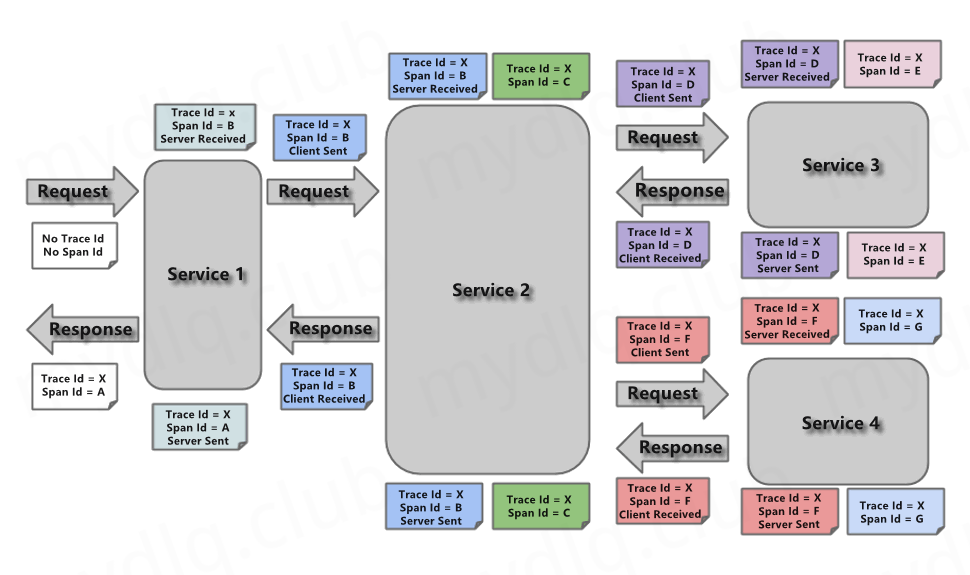
二、组件介绍
这里需要用到下面几个组件来完成链路追踪的整个流程,先简单分别介绍一下:
Kafka:
一个高性能消息队列,这里用于接收服务链路日志信息,异步操作减少峰值。
Kibana:
分析和可视化平台,设计用于分析、展示 Elasticsearch 中数据。
ElasticSearch:
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,能快速检索数据,这里用于存储链路日志信息。
SpringCloud Feign:
声明式的 web service 客户端,而 SpringCloud Feign 在这个基础上加上很多 SpringCloud 相关组件,当引入 Sleuth 组件时候能将链路日志信息进行服务间传递。
三、链路追踪部署流程
这里有两种部署流程,这里简单介绍下:
1、两种日志采集方式
- 方式一: 将链路日志直接推送到 Zipkin Server 进行聚合,存储到 ElasticSearch 中,最后再用 Zipkin UI 展示链路过程。
- 方式二: 将链路日志推送到 Kafka,然后启动 Zipkin Server 聚合日志,监听 Kafka ,如果有新的消息则进行拉取存入到 ElasticSeach,最后再用 Zipkin UI 展示链路过程。
两种方式的比较:
第一种方式使用与配置起来比较简单,并且在 Kubernetes 中能够很容易的横向扩展来处理一定的链路日志数据,不过如果服务过多,链路日志数据量过大还是可能造成 Zipkin Server 的崩溃,所以比较适合服务数量不大的境中。
第二种方式使用与配置比较复杂,需要 Kubernetes 集群中部署 Kafka 与 Zookeeper,通过将链路日志数据写入 Kafka 进行削峰,再由 Kafka 写入 Zipkin Server 进行聚合,所以比较适合数据量大、服务多的环境。
2、流程图
方式一:Zipkin Server + ElasticSearch

方式二:Zipkin Server + ElasticSearch + Kafka
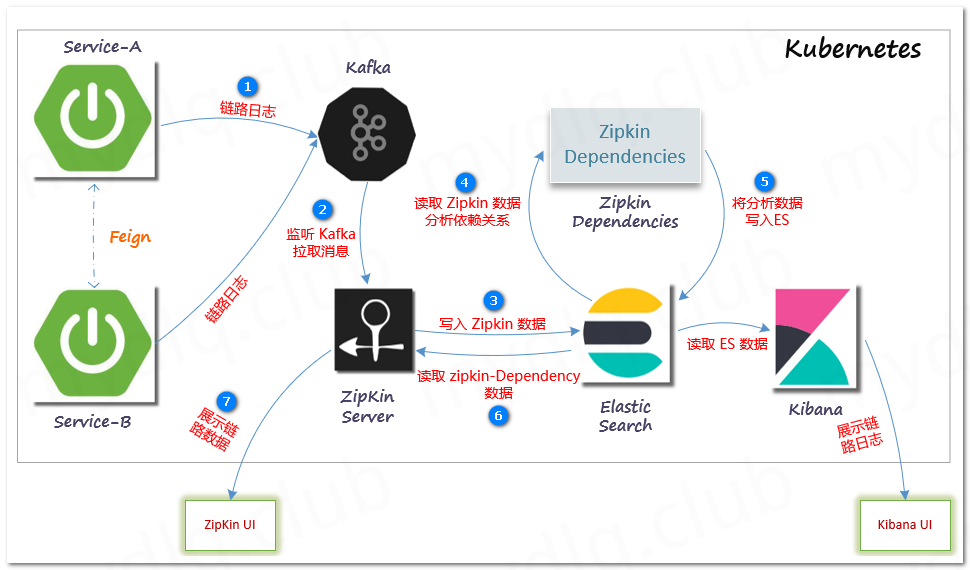
四、准备部署环境
在实际生产环境中,一般都需要配合 Kafka 完成链路工作,所以我们将围绕第二种来介绍,需要准备下面组件:
- Kafka: 需要拥有在 Kubernetes 环境中能访问的 Kafka 集群。
- ElasticSearch: 需要拥有在 Kubernetes 环境中能访问的 ElasticSearch 集群。
- Zipkin: 在 Kubernetes 中部署 Zipkin,后面将演示这个部署的过程。
- 两个 SpringCloud 服务: 需要两个 SpringCloud 服务,通过 Feign 相互调用接口产生链路日志便于测试,后面将演示如何写测试项目部署到 Kubernetes 中。
在 Kubernetes 中完成链路流程的方案,需要依赖上面各个组件,这些组件最好部署在 Kubernetes 中来保证稳定,关于如何在 Kubernetes 中部署 Kafka、ElasticSearch、Kibana 本人之前发的博文中已经有过部署流程,所以不再过度描述,如果 Kubernetes 集群外已经有能够使用的上面组件并且还能正常调用,直接调用即可。
接下来将演示在 Kubernetes 中部署 Zipkin 与两个 SpringCloud 服务,完成链路部署工作。
五、Kubernetes 部署 Zipkin
1、部署 Zipkin Server
Zipkin Server 是用于收集链路日志信息进行聚合,然后保存数据,并通过 UI 展示数据的组件,这里新建部署文件,然后执行 Kuberctl 命令在 Kubernetes 集群创建 Zipkin Server,并且由于 Zipkin Server 需要监听 Kafka,所以这里也要设置 Kafka 相关配置。
关于 Zipkin Server 配置参数,可以参考 Zipkin Server Github
zipkin-server.yaml
1apiVersion: v1
2kind: Service
3metadata:
4 name: zipkin
5 labels:
6 app: zipkin
7spec:
8 type: NodePort #指定为 NodePort 方式暴露出口
9 ports:
10 - name: server
11 port: 9411
12 targetPort: 9411
13 nodePort: 30190 #指定 Nodeport 端口
14 protocol: TCP
15 selector:
16 app: zipkin
17---
18apiVersion: apps/v1
19kind: Deployment
20metadata:
21 name: zipkin
22 labels:
23 name: zipkin
24spec:
25 replicas: 1
26 selector:
27 matchLabels:
28 app: zipkin
29 template:
30 metadata:
31 labels:
32 app: zipkin
33 spec:
34 containers:
35 - name: zipkin
36 image: openzipkin/zipkin:2.15
37 ports:
38 - containerPort: 9411
39 env:
40 - name: JAVA_OPTS
41 value: "
42 -Xms512m -Xmx512m
43 -Dlogging.level.zipkin=DEBUG
44 -Dlogging.level.zipkin2=DEBUG
45 -Duser.timezone=Asia/Shanghai
46 "
47 - name: STORAGE_TYPE
48 value: "elasticsearch" #设置数据存储在ES中
49 - name: ES_HOSTS
50 value: "elasticsearch-client.mydlqcloud:9200" #ES地址
51 - name: ES_INDEX #设置ES中存储的zipkin索引名称
52 value: "zipkin"
53 - name: ES_INDEX_REPLICAS #ES索引副本数
54 value: "1"
55 - name: ES_INDEX_SHARDS #ES分片数量
56 value: "3"
57 #- name: ES_USERNAME #如果ES启用x-pack,需要设置用户名、密码
58 # value: ""
59 #- name: ES_PASSWORD
60 # value: ""
61 - name: KAFKA_BOOTSTRAP_SERVERS #Kafka 地址
62 value: "kafka.mydlqcloud:9092"
63 - name: KAFKA_TOPIC #Kafka Topic名称,默认为"zipkin"
64 value: "zipkin"
65 - name: KAFKA_GROUP_ID #Kafka 组名,默认为"zipkin"
66 value: "zipkin"
67 - name: KAFKA_STREAMS #消耗Topic的线程数,默认为1
68 value: "1"
69 resources:
70 limits:
71 cpu: 1000m
72 memory: 512Mi
73 requests:
74 cpu: 500m
75 memory: 256Mi
部署 Zipkin-Server 到 Kubernetes
- -n:指定应用部署的 Namespace
1$ kubectl apply -f zipkin-server.yaml -n mydlqcloud
部署完成后就能通过集群 IP + NodePort 端口访问 Zipkin UI。可以看到 Zipkin 页面,这里我的 Kubernetes 集群地址为 192.168.2.11 ,上面指定的 NodePort 端口为 30190,所以输入地址 http://192.168.2.11:30190 访问 Zipkin UI,本人模拟写入一段链路数据来测试,不过只能看到 UI 界面 Traces 面板有服务间调用信息,点击 Dependency Links 没有发现服务间关联图标相关信息。
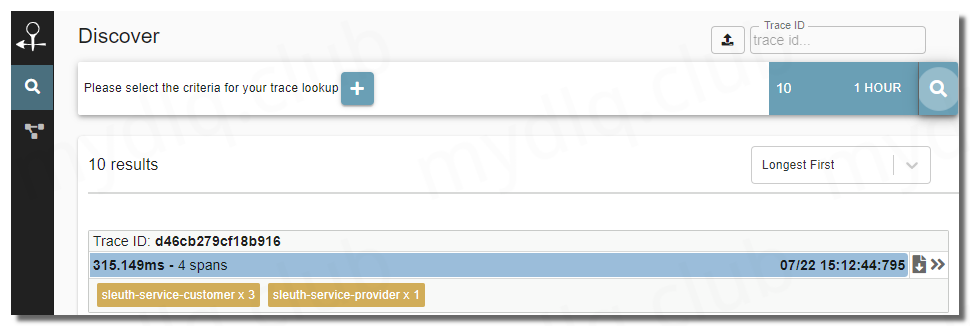
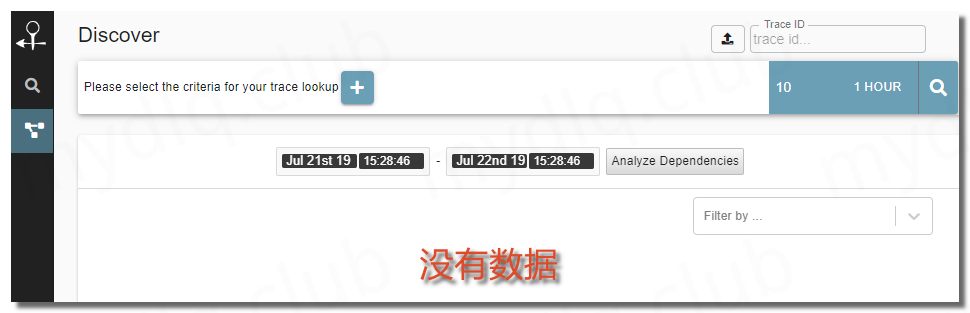
经过分析后原来是因为 Zipkin Server 只是负责收集聚合、存储数据到数据库,并不会分析服务间依赖关系,需要展示这一部分图标还需要部署 zipkin-dependencies 后再回到当前 UI 界面查看。
2、部署 Zipkin-Dependencies
zipkin-dependencies 是一个聚合数据依赖关系的服务,这里启动服务后它会自动从 ElasticSearch 中获取索引,分析依赖关系然后再以 zipkin索引名称-dependency-yyyy-mm-dd 命名创建新索引存入 ElasticSearch。
并且这个服务内置 Crond 定时任务,默认每隔一小时会执行分析 ElasticSearch 中索引关系的任务(在 Kubernetes 中将其设置一个 Job 任务来使用也是可以的,因为它每次启动时候都会先进行分析依赖数据,当然也可以用容器内部的 Crond 来执行定时任务)。
注意:下面 yaml 中一定要设置 command 命令来启用 crond 定时任务,否则之后执行一次分析依赖关系任务后程序自动关闭。
zipkin-dependencies.yaml
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: zipkin-dependencies
5 labels:
6 name: zipkin-dependencies
7spec:
8 replicas: 1
9 selector:
10 matchLabels:
11 app: zipkin-dependencies
12 template:
13 metadata:
14 labels:
15 app: zipkin-dependencies
16 spec:
17 containers:
18 - name: zipkin
19 image: openzipkin/zipkin-dependencies:2.3.1
20 ports:
21 - containerPort: 80
22 command: ["sh","-c","crond -f"]
23 env:
24 - name: JAVA_OPTS
25 value: "-Xms512m -Xmx512m"
26 - name: STORAGE_TYPE
27 value: "elasticsearch"
28 - name: ES_HOSTS
29 value: "elasticsearch-client.mydlqcloud:9200"
30 - name: ES_INDEX #设置ES中存储的zipkin索引名称
31 value: "zipkin"
32 #- name: ES_USERNAME #如果ES启用x-pack,需要设置用户名、密码
33 # value: ""
34 #- name: ES_PASSWORD
35 # value: ""
36 resources:
37 limits:
38 cpu: 1000m
39 memory: 512Mi
40 requests:
41 cpu: 500m
42 memory: 256Mi
部署 Zipkin-Dependencies 到 Kubernetes
- -n:指定应用部署的 Namespace
1$ kubectl apply -f zipkin-dependencies.yaml -n mydlqcloud
部署完成后再次打开 Zipkin UI 界面,点击进入 Dependency Links,然后按下分析按钮后出现链路依赖关系图。

六、Kubernetes 部署 SpringCloud 服务
这里在 Kubernetes 中部署基于 SpringBoot 的sleuth-service-provider与sleuth-service-customer服务,引入 SpringCloud Feign、SprinCloud Sleuth、Zipkin、Kafka、等组件,两个服务间相互调用产生链路日志信息。
1、创建 sleuth-service-provider 服务
Maven 引入相关 Jar 依赖
1<?xml version="1.0" encoding="UTF-8"?>
2<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
3 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
4 <modelVersion>4.0.0</modelVersion>
5
6 <parent>
7 <groupId>org.springframework.boot</groupId>
8 <artifactId>spring-boot-starter-parent</artifactId>
9 <version>2.1.6.RELEASE</version>
10 <relativePath/>
11 </parent>
12
13 <groupId>club.mydlq</groupId>
14 <artifactId>sleuth-service-provider</artifactId>
15 <version>0.0.1</version>
16 <name>sleuth-service-provider</name>
17 <description>sleuth service provider</description>
18
19 <properties>
20 <java.version>1.8</java.version>
21 </properties>
22
23 <dependencies>
24 <!--SpringBoot Web-->
25 <dependency>
26 <groupId>org.springframework.boot</groupId>
27 <artifactId>spring-boot-starter-web</artifactId>
28 </dependency>
29 <!--SpringBoot Actuator-->
30 <dependency>
31 <groupId>org.springframework.boot</groupId>
32 <artifactId>spring-boot-starter-actuator</artifactId>
33 </dependency>
34 <!--Seluth-->
35 <dependency>
36 <groupId>org.springframework.cloud</groupId>
37 <artifactId>spring-cloud-starter-sleuth</artifactId>
38 <version>2.1.2.RELEASE</version>
39 </dependency>
40 <!--Zipkin-->
41 <dependency>
42 <groupId>org.springframework.cloud</groupId>
43 <artifactId>spring-cloud-starter-zipkin</artifactId>
44 <version>2.1.2.RELEASE</version>
45 </dependency>
46 <!--Kafka-->
47 <dependency>
48 <groupId>org.springframework.kafka</groupId>
49 <artifactId>spring-kafka</artifactId>
50 </dependency>
51 </dependencies>
52
53 <build>
54 <plugins>
55 <plugin>
56 <groupId>org.springframework.boot</groupId>
57 <artifactId>spring-boot-maven-plugin</artifactId>
58 </plugin>
59 </plugins>
60 </build>
61
62</project>
Provider 服务配置文件
创建 application.yaml 配置文件加入下面配置:
1server:
2 port: 8080
3
4management:
5 server:
6 port: 8081
7 endpoints:
8 web:
9 exposure:
10 include: "*"
11
12spring:
13 application:
14 name: sleuth-service-provider
15 sleuth:
16 sampler:
17 probability: 1.0 #采集率,最大1.0(百分百采集),默认0.1(百分之十采集)
18 zipkin:
19 #base-url: http://192.168.2.11:30190 #Zipkin Server地址,这里使用了Kafka所以被注掉
20 sender:
21 type: kafka #指定发送到kafka,还可以指定Rabbit、Web
22 service:
23 name: ${spring.application.name} #Zipkin链路日志中收集的服务名称
24 kafka:
25 bootstrap-servers: kafka.mydlqcloud:9092 #Kubernetes中Kakfa 地址,当然也可以指定 Kubernetes集群外的 Kafka 地址
Controller 类中写一个供 Consumer 使用 Feign 调用的接口
1import org.springframework.web.bind.annotation.GetMapping;
2import org.springframework.web.bind.annotation.RestController;
3
4@RestController
5public class SleuthController {
6
7 @GetMapping("/")
8 public String getSleuthInfo() {
9 return "链路测试";
10 }
11
12}
启动类
1import org.springframework.boot.SpringApplication;
2import org.springframework.boot.autoconfigure.SpringBootApplication;
3
4@SpringBootApplication
5public class Application {
6
7 public static void main(String[] args) {
8 SpringApplication.run(Application.class, args);
9 }
10
11}
2、创建 sleuth-service-customer 服务
Maven 引入相关 Jar 依赖
1<?xml version="1.0" encoding="UTF-8"?>
2<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
3 xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
4 <modelVersion>4.0.0</modelVersion>
5
6 <parent>
7 <groupId>org.springframework.boot</groupId>
8 <artifactId>spring-boot-starter-parent</artifactId>
9 <version>2.1.6.RELEASE</version>
10 <relativePath/>
11 </parent>
12
13 <groupId>club.mydlq</groupId>
14 <artifactId>sleuth-service-customer</artifactId>
15 <version>0.0.1</version>
16 <name>sleuth-service-customer</name>
17 <description>sleuth service customer</description>
18
19 <properties>
20 <java.version>1.8</java.version>
21 </properties>
22
23 <dependencies>
24 <!--SpringBoot Web-->
25 <dependency>
26 <groupId>org.springframework.boot</groupId>
27 <artifactId>spring-boot-starter-web</artifactId>
28 </dependency>
29 <!--SpringBoot Actuator-->
30 <dependency>
31 <groupId>org.springframework.boot</groupId>
32 <artifactId>spring-boot-starter-actuator</artifactId>
33 </dependency>
34 <!--Feign-->
35 <dependency>
36 <groupId>org.springframework.cloud</groupId>
37 <artifactId>spring-cloud-starter-openfeign</artifactId>
38 <version>2.1.2.RELEASE</version>
39 </dependency>
40 <!--Seluth-->
41 <dependency>
42 <groupId>org.springframework.cloud</groupId>
43 <artifactId>spring-cloud-starter-sleuth</artifactId>
44 <version>2.1.2.RELEASE</version>
45 </dependency>
46 <!--Zipkin-->
47 <dependency>
48 <groupId>org.springframework.cloud</groupId>
49 <artifactId>spring-cloud-starter-zipkin</artifactId>
50 <version>2.1.2.RELEASE</version>
51 </dependency>
52 <!--Kafka-->
53 <dependency>
54 <groupId>org.springframework.kafka</groupId>
55 <artifactId>spring-kafka</artifactId>
56 </dependency>
57 </dependencies>
58
59 <build>
60 <plugins>
61 <plugin>
62 <groupId>org.springframework.boot</groupId>
63 <artifactId>spring-boot-maven-plugin</artifactId>
64 </plugin>
65 </plugins>
66 </build>
67
68</project>
Customer 服务配置文件
创建 application.yaml 配置文件加入下面配置:
1server:
2 port: 8080
3
4management:
5 server:
6 port: 8081
7 endpoints:
8 web:
9 exposure:
10 include: "*"
11
12spring:
13 application:
14 name: sleuth-service-customer
15 sleuth:
16 sampler:
17 probability: 1.0 #采集率,最大1.0(百分百采集),默认0.1(百分之十采集)
18 zipkin:
19 #base-url: http://192.168.2.11:30190 #Zipkin Server地址,这里使用了Kafka所以被注掉
20 sender:
21 type: kafka #指定发送到kafka,还可以指定Rabbit、Web
22 service:
23 name: ${spring.application.name} #Zipkin链路日志中收集的服务名称
24 kafka:
25 bootstrap-servers: kafka.mydlqcloud:9092 #Kubernetes中Kakfa地址,当然也可以指定Kubernetes集群外的Kafka地址
Feign 调用 Provider 服务的接口类
配置 Feign 接口指向调用 sleuth-service-provider 服务接口
1import org.springframework.cloud.openfeign.FeignClient;
2import org.springframework.web.bind.annotation.GetMapping;
3
4@FeignClient(name = "http://sleuth-service-provider:8080", url = "http://sleuth-service-provider:8080")
5public interface ProviderService {
6
7 @GetMapping("/")
8 public String getSleuthInfo();
9
10}
Controller 类中写一个调用 Feign 的接口
1import club.mydlq.k8s.feign.ProviderService;
2import org.springframework.beans.factory.annotation.Autowired;
3import org.springframework.web.bind.annotation.*;
4
5@RestController
6public class SleuthController {
7
8 @Autowired
9 private ProviderService providerService;
10
11 @GetMapping("/")
12 public String getInfo(){
13 return providerService.getSleuthInfo();
14 }
15
16}
启动类
引入 @EnableFeignClients 注解开启 Feign
1import org.springframework.boot.SpringApplication;
2import org.springframework.boot.autoconfigure.SpringBootApplication;
3import org.springframework.cloud.openfeign.EnableFeignClients;
4
5@SpringBootApplication
6@EnableFeignClients
7public class Application {
8
9 public static void main(String[] args) {
10 SpringApplication.run(Application.class, args);
11 }
12
13}
3、准备 Kubernetes 部署文件
在 Kubernetes 中部署服务需要两个部署的 yaml 文件,分别为 sleuth-service-provider.yaml、sleuth-service-customer.yaml。
sleuth-service-provider.yaml
1apiVersion: v1
2kind: Service
3metadata:
4 name: sleuth-service-provider
5spec:
6 type: NodePort
7 ports:
8 - name: server
9 nodePort: 31005
10 port: 8080
11 targetPort: 8080
12 - name: management
13 nodePort: 31006
14 port: 8081
15 targetPort: 8081
16 selector:
17 app: sleuth-service-provider
18---
19apiVersion: apps/v1
20kind: Deployment
21metadata:
22 name: sleuth-service-provider
23 labels:
24 app: sleuth-service-provider
25spec:
26 replicas: 1
27 selector:
28 matchLabels:
29 app: sleuth-service-provider
30 template:
31 metadata:
32 name: sleuth-service-provider
33 labels:
34 app: sleuth-service-provider
35 spec:
36 restartPolicy: Always #为了方便测试,设置镜像每次都从新拉取新镜像
37 containers:
38 - name: sleuth-service-provider
39 image: registry.cn-beijing.aliyuncs.com/mydlq/sleuth-service-provider:0.0.1
40 imagePullPolicy: IfNotPresent
41 ports:
42 - containerPort: 8080
43 name: server
44 - containerPort: 8081
45 name: management
46 resources:
47 limits:
48 memory: 256Mi
49 cpu: 1000m
50 requests:
51 memory: 128Mi
52 cpu: 500m
sleuth-service-customer.yaml
1apiVersion: v1
2kind: Service
3metadata:
4 name: sleuth-service-customer
5spec:
6 type: NodePort #通过NodePort方式暴露服务
7 ports:
8 - name: server
9 nodePort: 31007 #设置NodePort端口为31007
10 port: 8080
11 targetPort: 8080
12 - name: management
13 nodePort: 31008
14 port: 8081
15 targetPort: 8081
16 selector:
17 app: sleuth-service-customer
18---
19apiVersion: apps/v1
20kind: Deployment
21metadata:
22 name: sleuth-service-customer
23 labels:
24 app: sleuth-service-customer
25spec:
26 replicas: 1
27 selector:
28 matchLabels:
29 app: sleuth-service-customer
30 template:
31 metadata:
32 name: sleuth-service-customer
33 labels:
34 app: sleuth-service-customer
35 spec:
36 restartPolicy: Always #为了方便测试,设置镜像每次都从新拉取新镜像
37 containers:
38 - name: sleuth-service-customer
39 image: registry.cn-beijing.aliyuncs.com/mydlq/sleuth-service-customer:0.0.1
40 imagePullPolicy: IfNotPresent
41 ports:
42 - containerPort: 8080
43 name: server
44 - containerPort: 8081
45 name: management
46 resources:
47 limits:
48 memory: 256Mi
49 cpu: 1000m
50 requests:
51 memory: 128Mi
52 cpu: 500m
4、部署服务到 Kubernetes 集群
执行 Kubectl 命令,部署两个服务到 Kubernetes 集群中:
-n:指定应用部署的 Namespace
1#部署 sleuth-service-provider 服务
2$ kubectl apply -f sleuth-service-provider.yaml -n mydlqcloud
3
4#部署 sleuth-service-customer 服务
5$ kubectl apply -f sleuth-service-customer.yaml -n mydlqcloud
七、测试查看链路信息
两个 SpringBoot 应用部署完成以后,将进行测试,首先需要调用服务 sleuth-service-customer 接口,让其通过 Feign 调用 Kubernetes 中服务 sleuth-service-provider 产生链路日志写入 Kafka,然后再查看 Kibana 中查看 ElasticSearch 中是否有对应以 zipkin 命名的索引生成,且能查询到链路日志。最后在查看 Zipkin UI 是否有链路信息。
各组件信息:
- Kubernetes 地址:192.168.2.11
- Zipkin UI NodePort 地址:192.168.2.11:30190
- Kibana UI NodePort 地址:192.168.2.11:31537
- sleuth-service-customer NodePort 端口:192.168.2.11:31007
(1)、调用服务接口产生链路日志
输入地址:http://192.168.2.11:31007 调用 sleuth-service-customer 接口,由于上面设置的链路日志采集率为 0.1 ,所以调用十次接口才会生成一条链路日志信息,所以这里我们最好多访问写次数。
(2)、配置 Kibana 索引模式,方便在 Kibana 中查看链路日志信息
本人这里 Kibana与ElasticSearch 部署在 Kubernetes 中,且 Kibana 地址为:192.168.2.11:31537,打开这个地址访问 Kibana,然后进入 Management 选项,配置 Index Patterns ,将 zipkin 索引加入其中。
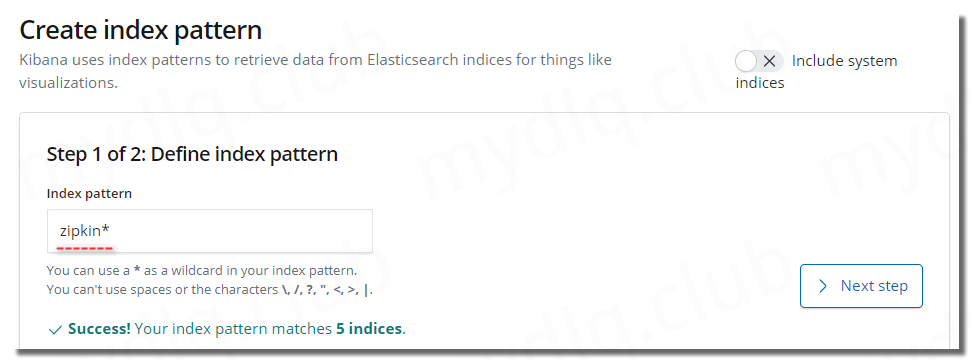
配置完成后进入 Discocer 界面查看链路日志数据:

(3)、进入 Zipkin UI 查看链路信息
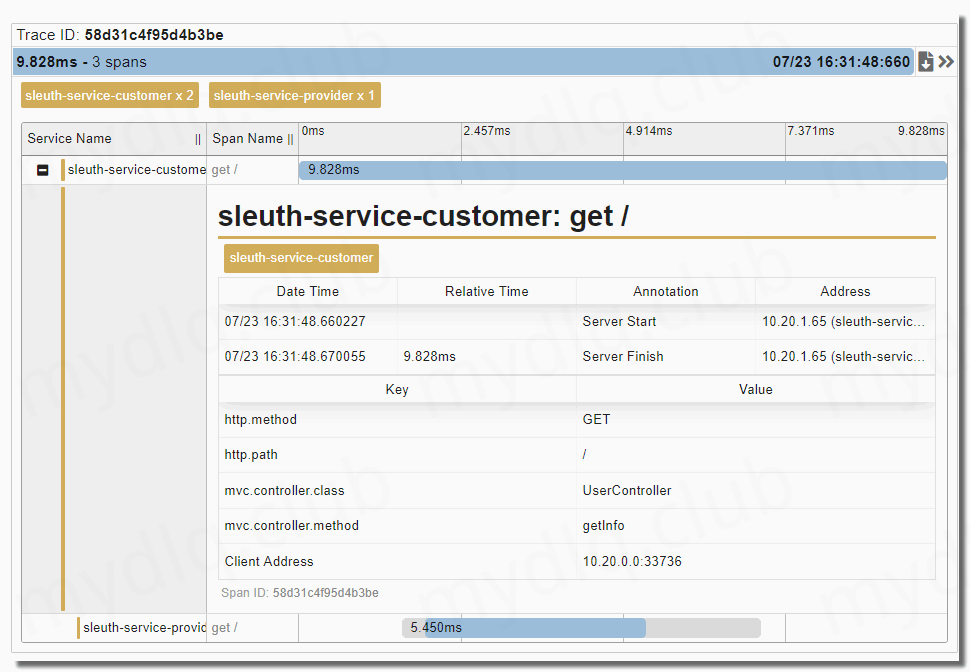
如果上面 Kibana 中已经能看到链路日志信息了,代表链路日志信息已经存入 Kibana 中,否则请检查 Kafka与Zipkin Server 配置是否正确。
如果都没有问题,那么访问 Zipkin UI,输入地址:http://192.168.2.11:30190,选择一小时内的数据,点击查找按钮后能搜索出来几条链路数据,点开查看,能看到这个链路携带的日志信息。

---END---

!版权声明:本博客内容均为原创,每篇博文作为知识积累,写博不易,转载请注明出处。