
Kubernetes 部署告警工具 AlertManager
文章目录
!版权声明:本博客内容均为原创,每篇博文作为知识积累,写博不易,转载请注明出处。
系统环境:
- 操作系统: CentOS 7.9
- Docker 版本: 20.10.8
- Prometheus 版本: 2.29.1
- Kubernetes 版本: 1.23.6
- AlertManager 版本: 0.24.0
参考地址:
示例地址:
系列文章目录
- 01. Kubernetes 部署监控工具 Prometheus
- 02. Kubernetes 部署图表工具 Grafana
- 03. Prometheus 结合 Node Exporter 监控 Kubernetes 集群节点
- 04. Prometheus 结合 StateMetrics+cAdvisor 监控 Kubernetes 集群服务
- 05. Prometheus 监听指定标签 Kubernetes 服务
- 06. Prometheus 监控 Kubernetes ETCD 集群
- 07. Prometheus Exporter 黑盒监控 Kubernetes 服务
- 08. Kubernetes 部署告警工具 AlertManager
- 09. AlertManager 配置邮箱告警
- 其它章节整理中...
一、AlertManager 简介
AlertManager 是一个专门用于实现告警的工具,可以实现接收 Prometheus 或其它应用发出的告警信息,并且可以对这些告警信息进行 分组、抑制 以及 静默 等操作,然后通过 路由 的方式,根据不同的告警规则配置,分发到不同的告警路由策略中。
除此之外,AlertManager 还支持 "邮件"、"企业微信"、"Slack"、"WebHook" 等多种方式发送告警信息,并且其中 WebHook 这种方式可以将告警信息转发到我们自定义的应用中,使我们可以对告警信息进行处理,所以使用 AlertManager 进行告警,非常方便灵活、简单易用。
AlertManager 常用的功能主要有:
- 抑制: 抑制是一种机制,指的是当某一告警信息发送后,可以停止由此告警引发的其它告警,避免相同的告警信息重复发送。
- 静默: 静默也是一种机制,指的是依据设置的标签,对告警行为进行静默处理。如果 AlertManager 接收到的告警符合静默配置,则 Alertmanager 就不会发送该告警通知。
- 发送告警: 支持配置多种告警规则,可以根据不同的路由配置,采用不同的告警方式发送告警通知。
- 告警分组: 分组机制可以将详细的告警信息合并成一个通知。在某些情况下,如系统宕机导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警信息合并为一个告警通知,从而避免一次性发送大量且属于相同问题的告警,导致无法对问题进行快速定位。
其中 Prometheus 和 AlertManager 的关系如下图所示:

二、创建 Kubernetes 部署 AlertManager 存储资源
这里使用的是 NFS 方式的 PV,需要存在 NFS Server 端才行,如果使用其它存储,请自行按照对应的存储方式进行配置 PV 参数,并且还需要注意配置文件夹的读写权限。
在 Kubernetes 中部署 AlertManager 之前,先创建一下用于存储 AlertManager 数据的 PV 和 PVC 资源文件 alertmanager-storage.yaml,内容如下:
alertmanager-storage.yaml
1apiVersion: v1
2kind: PersistentVolume
3metadata:
4 name: alertmanager
5 labels:
6 k8s-app: alertmanager
7spec:
8 capacity:
9 storage: 2Gi
10 accessModes:
11 - ReadWriteOnce
12 persistentVolumeReclaimPolicy: Retain
13 storageClassName: nfs-storage
14 mountOptions:
15 - hard
16 - nfsvers=4.1
17 nfs:
18 path: /nfs/alertmanager
19 server: 192.168.2.11
20---
21kind: PersistentVolumeClaim
22apiVersion: v1
23metadata:
24 name: alertmanager
25 labels:
26 k8s-app: alertmanager
27spec:
28 accessModes:
29 - ReadWriteOnce
30 storageClassName: nfs-storage
31 resources:
32 requests:
33 storage: 2Gi
34 selector:
35 matchLabels:
36 k8s-app: alertmanager
将 PV/PVC 资源文件部署到 Kubernetes 中,执行的命令如下:
- -f: 指定部署的资源文件;
- -n: 指定部署的命名空间;
1$ kubectl apply -f alertmanager-storage.yaml -n kube-system
三、创建 Kubernetes 部署 AlertManager 配置
创建 AlertManager 配置文件 alertmanager-config.yaml,内容如下:
alertmanager-config.yaml
1apiVersion: v1
2kind: ConfigMap
3metadata:
4 name: alertmanager-config
5data:
6 alertmanager.yml: |-
7 global:
8 ## 持续多少时间没有触发告警,则认为处于告警问题已经解决状态的时间
9 resolve_timeout: 5m
10 ## 配置邮件发送信息
11 smtp_smarthost: '邮箱服务器,如163邮箱为smtp.163.com:25'
12 smtp_from: '发送邮件的账户'
13 smtp_auth_username: '发送邮件的email用户名'
14 smtp_auth_password: '发送邮件的email的TOKEN秘钥'
15 smtp_require_tls: false
16 # 所有报警信息进入后的根路由,用来设置报警的分发策略
17 route:
18 ## 这里的标签列表是接收到报警信息后的重新分组标签,例如接收到的报警信息里面有许多具有 cluster=A 这样的标签,可以根据这些标签,将告警信息批量聚合到一个分组里面中
19 group_by: ['alertname', 'cluster']
20 ## 当一个新的报警分组被创建后,需要等待至少group_wait时间来初始化通知,这种方式可以确保能有足够的时间为同一分组来汇入尽可能多的告警信息,然后将这些汇集的告警信息一次性触发
21 group_wait: 30s
22 ## 当第一个报警发送后,等待 group_interval 时间来发送新的一组报警信息
23 group_interval: 5m
24 ## 如果一个报警信息已经发送成功了,则需要等待 repeat_interval 时间才能重新发送
25 repeat_interval: 5m
26 ## 配置默认的路由规则
27 receiver: default
28 ## 配置子路由规则,如果一个告警没有被任何一个子路由规则匹配,就会使用default配置
29 #routes:
30 #- receiver: webhook
31 # group_wait: 10s
32 # match:
33 # team: node
34 receivers:
35 - name: 'default'
36 email_configs:
37 - to: 'xxxxxx@163.com,即接收告警邮件的邮箱地址'
38 send_resolved: true
将上面存储着 AlertManager 配置文件的 ConfigMap 资源部署到 Kubernetes 中,执行的命令如下:
- -f: 指定部署的资源文件;
- -n: 指定部署的命名空间;
1$ kubectl apply -f alertmanager-config.yaml -n kube-system
四、Kubernetes 部署 AlertManager 应用
4.1 部署 AlertManager 应用
创建 AlertManager 部署文件 alertmanager-deploy.yaml,内容如下:
alertmanager-deploy.yaml
1apiVersion: v1
2kind: Service
3metadata:
4 name: alertmanager
5 labels:
6 k8s-app: alertmanager
7spec:
8 type: NodePort
9 ports:
10 - name: http
11 port: 9093
12 targetPort: 9093
13 nodePort: 30903
14 selector:
15 k8s-app: alertmanager
16---
17apiVersion: apps/v1
18kind: Deployment
19metadata:
20 name: alertmanager
21 labels:
22 k8s-app: alertmanager
23spec:
24 replicas: 1
25 selector:
26 matchLabels:
27 k8s-app: alertmanager
28 template:
29 metadata:
30 labels:
31 k8s-app: alertmanager
32 spec:
33 containers:
34 - name: alertmanager
35 image: prom/alertmanager:v0.24.0
36 ports:
37 - name: http
38 containerPort: 9093
39 args:
40 ## 指定容器中AlertManager配置文件存放地址 (Docker容器中的绝对位置)
41 - "--config.file=/etc/alertmanager/alertmanager.yml"
42 ## 指定AlertManager管理界面地址,用于在发生的告警信息中,附加AlertManager告警信息页面地址
43 - "--web.external-url=http://192.168.2.11:30903"
44 ## 指定监听的地址及端口
45 - '--cluster.advertise-address=0.0.0.0:9093'
46 ## 指定数据存储位置 (Docker容器中的绝对位置)
47 - "--storage.path=/alertmanager"
48 resources:
49 limits:
50 cpu: 1000m
51 memory: 512Mi
52 requests:
53 cpu: 1000m
54 memory: 512Mi
55 readinessProbe:
56 httpGet:
57 path: /-/ready
58 port: 9093
59 initialDelaySeconds: 5
60 timeoutSeconds: 10
61 livenessProbe:
62 httpGet:
63 path: /-/healthy
64 port: 9093
65 initialDelaySeconds: 30
66 timeoutSeconds: 30
67 volumeMounts:
68 - name: data
69 mountPath: /alertmanager
70 - name: config
71 mountPath: /etc/alertmanager
72 - name: configmap-reload
73 image: jimmidyson/configmap-reload:v0.7.1
74 args:
75 - "--volume-dir=/etc/config"
76 - "--webhook-url=http://localhost:9093/-/reload"
77 resources:
78 limits:
79 cpu: 100m
80 memory: 100Mi
81 requests:
82 cpu: 100m
83 memory: 100Mi
84 volumeMounts:
85 - name: config
86 mountPath: /etc/config
87 readOnly: true
88 volumes:
89 - name: data
90 persistentVolumeClaim:
91 claimName: alertmanager
92 - name: config
93 configMap:
94 name: alertmanager-config
将上面部署 AlertManager 的资源署到 Kubernetes 中,执行的命令如下:
- -f: 指定部署的资源文件;
- -n: 指定部署的命名空间;
1$ kubectl apply -f alertmanager-deploy.yaml -n kube-system
4.2 访问 AlertManager 管理界面
上面在部署 Prometheus 中设置其 Service 模式为 NodePort 模式,端口号为 30903,所以我们可以使用 NodePort 的端口访问 AlertManager。
这里本人的 Kubernetes 集群中的其中一个地址为 192.168.2.11,所以我们可以输入地址 http://192.168.2.11:30903 访问 Prometheus 页面,就可以看到如下界面:
五、Prometheus 添加告警配置
5.1 Prometheus 配置 AlertManager 配置和 Rules 告警规则
本人部署的 Prometheus 是完全按照之前写的 Kubernetes 部署 Prometheus 文章进行部署的,在那篇文章中使用了 ConfigMap 资源存储 Prometheus 配置文件,所以这里需要对 Prometheus 配置文件进行改动,就需要修改 ConfigMap 资源文件 prometheus-config.yaml,改动内容如下:
- (1) 添加 AlertManager 服务器地址;
- (2) 指定告警规则文件路径位置;
- (3) 添加 Prometheus 中触发告警的告警规则;
prometheus-config.yaml
1apiVersion: v1
2kind: ConfigMap
3metadata:
4 name: prometheus-config
5data:
6 prometheus.yml: |
7 global:
8 scrape_interval: 15s
9 evaluation_interval: 15s
10 external_labels:
11 cluster: "kubernetes"
12
13 scrape_configs:
14 - job_name: prometheus
15 static_configs:
16 - targets: ['127.0.0.1:9090']
17 labels:
18 instance: prometheus
19
20 ############ 添加配置 AlertManager 服务器地址 ###################
21 alerting:
22 alertmanagers:
23 - static_configs:
24 - targets: ["alertmanager.kube-system:9093"]
25
26 ############ 指定告警规则文件路径位置 ###################
27 rule_files:
28 - /etc/prometheus/*-rule.yml
29
30 ## 新增告警规则文件,可以参考: https://prometheus.io/docs/alerting/latest/notification_examples/
31 test-rule.yml: |
32 groups:
33 - name: Instances
34 rules:
35 - alert: InstanceDown
36 expr: up == 0
37 for: 5m
38 labels:
39 severity: page
40 annotations:
41 description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.'
42 summary: 'Instance {{ $labels.instance }} down'
然后重新部署存储 Prometheus 配置文件的 ConfigMap 资源,执行的命令如下:
1$ kubectl apply -f prometheus-config.yaml -n kube-system
再之后重启 Prometheus,使其重新加载新的 配置 和 告警规则 文件,命令如下:
1## 缩放副本到 0 使 Prometheus Pod 关闭
2$ kubectl scale deployment prometheus --replicas=0 -n kube-system
3
4## 扩展副本到 1 使 Prometheus Pod 启动
5$ kubectl scale deployment prometheus --replicas=1 -n kube-system
5.2 通过 Prometheus Dashboard 观察配置和告警规则是否生效
打开 Prometheus 界面,观察 Configuration配置页面、Rules告警规则页面 和 Alerts告警状态页面,以便确认新增加的配置和告警规则是否生效。
配置文件 (Configuration界面)

告警规则 (Rules界面)

告警状态 (Alerts界面)
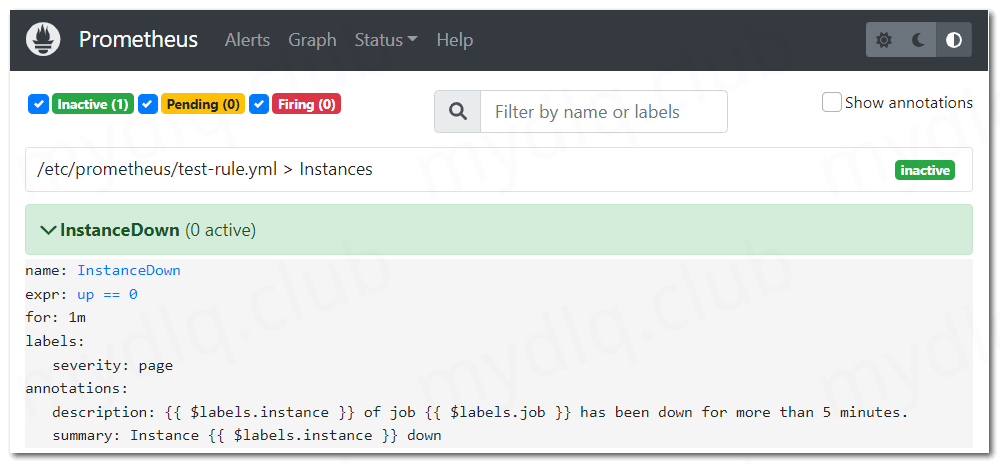
通过以上三个页面,就可以判断规则已经生效,不过需要提前说明的是,由于上面设置的告警规则中的告警条件为 up == 0,意思就是当全部 Prometheus 监控的应用健康状态都为 0 不健康状态时才会触发告警。
但是又因为上面 Prometheus 配置文件中设置了监控 Prometheus 自身,而 Prometheus 正常运行时指标 up 的值至少为 1,即 up > 0,所以告警状态从始至终都为没有触发告警的 inactive 状态。
六、进行告警测试
接下来我们为了测试告警功能,需要使 Prometheus 触发告警规则,如果告警规则被触发,告警状态将从 inactive 状态改变为 Pending 状态,等待一段时间,如果告警规则仍然满足,告警状态将从 Pending 状态改变为 Firing 状态,这时 Prometheus 会将告警信息发生到 AlertManager 中。
AlertManager 接收到告警规则后,会根据信息判断是否执行告警,并且根据配置不同的告警规则使用不同的方式发生告警信息,比如 发送告警邮件、触发企业微信告警、触发自定义 WebHook 等。
6.1 修改 Prometheus 告警规则配置
为了方便触发 Prometheus 中的告警规则,所以我们将上面配置的告警规则中的 up == 0 修改为 up > 0,确保现有 Prometheus 中的指标值能够触发告警,修改后的 Prometheus 配置文件如下:
prometheus-config.yaml
1apiVersion: v1
2kind: ConfigMap
3metadata:
4 name: prometheus-config
5data:
6 prometheus.yml: |
7 ......
8 test-rule.yml: |
9 ## ...... 修改告警规则,内容如下:
10 groups:
11 - name: Instances
12 ## 将 up == 0 修改为 up > 0,如下:
13 rules:
14 - alert: InstanceDown
15 expr: up > 0
16 for: 5m
17 labels:
18 severity: page
19 annotations:
20 description: '{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.'
21 summary: 'Instance {{ $labels.instance }} down'
然后使用下面命令,重新部署存储 Prometheus 的 ConfigMap 资源:
1$ kubectl apply -f prometheus-config.yaml -n kube-system
由于之前在 Kubernetes 中部署的 Prometheus Pod 中,部署容器由 Prometheus 和 configmap-reload 两个容器组成一个 Pod,其中 configmap-reload 容器的作用就是监听配置文件的更改,当我们修改配置文件后,等待一段时间,该容器应用会自动重新加载该配置。
6.2 观察 Prometheus 页面中的告警规则和状态
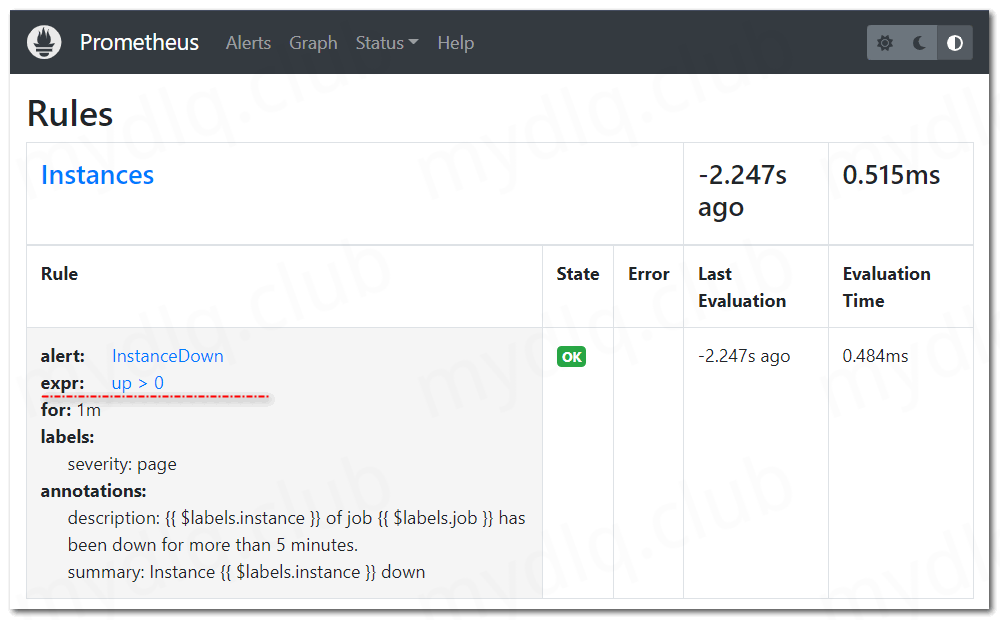
重新部署完 Prometheus 配置文件的 ConfigMap 资源后,等待一段时间,等到上面我们部署 AlertManager 时配置的 configmap-reload 容器监听到配置文件发生变化,然后重新加载配置文件时(最晚几分钟时间),我们再访问 Prometheus Dashboard 页面中的 Status->Rules 页面,会看到如下规则:
这时,我们可以访问 Alerts 页面观察是否有触发的告警规则,能看到告警规则状态如下图所示:
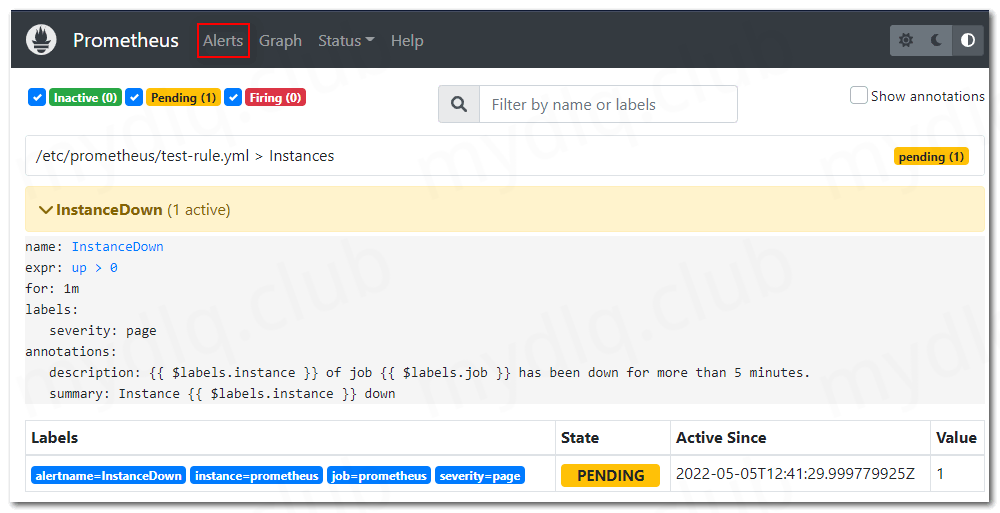
然后进行等待,如果 Prometheus 中的指标 up > 0 值在一分钟内持续成立,那么配置的告警规则状态将变为 FIRING,如下图所示:
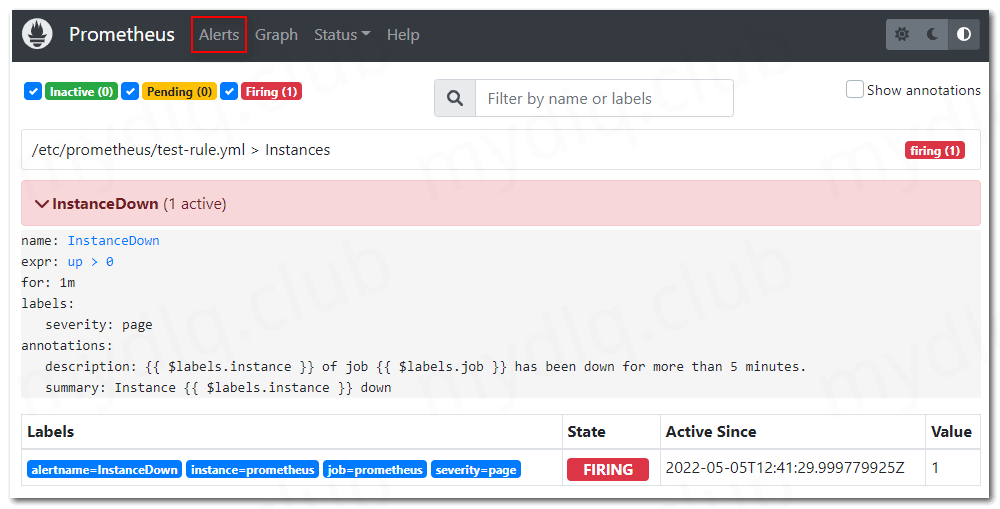
当告警状态变为 FIRING 时,告警信息已经发送配置的 AlertManager 地址中,让其代为发送告警信息。
6.3 观察 AlertManager 页面中的告警信息
打开 AlertManager 告警页面,可以观察到已经存在一条告警信息,内容如下:
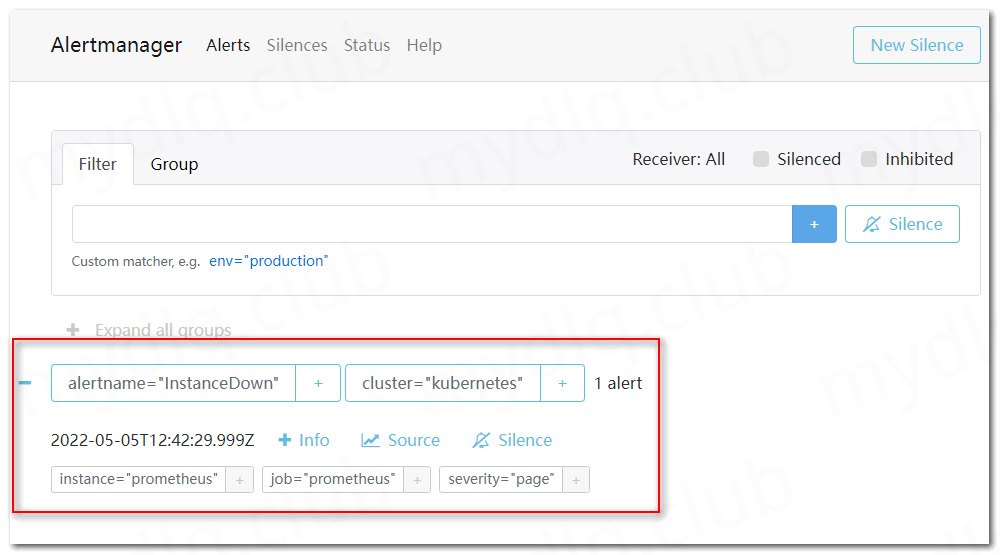
看到上图中的这条信息,则说明 AlertManager 已经成功发送告警信息,所以我们查看配置的接受者的邮箱,是否成功接收到告警邮件。
6.4 查看邮箱中的告警邮件
打开邮箱,如果发现如下图所示的告警邮件,则说明整个流程已经跑通。

剩下的就是对 Prometheus 中的告警规则进行调试,按照自己配置的告警规则触发告警,再者就是配置 AlertManager,设置多久不重复发送告警,是否静音,以及通过什么方式方法告警等等。
---END---
如果本文对你有帮助,可以关注我的公众号"小豆丁技术栈"了解最新动态,顺便也请帮忙 github 点颗星哦~感谢~

!版权声明:本博客内容均为原创,每篇博文作为知识积累,写博不易,转载请注明出处。